This page collects Rust snippets for the
rust-data-processing crate. The repository README leads with Python; Python
mirrors many of these examples in docs/python/README.md,
including Phase 2 copy-paste blocks in docs/python/PHASE2_EXAMPLES.md
(JSONL export, privacy transforms, median, Delta handoff). JVM JSON
parity examples live in docs/java/EXAMPLES.md. For
the conceptual API surface see API.md.
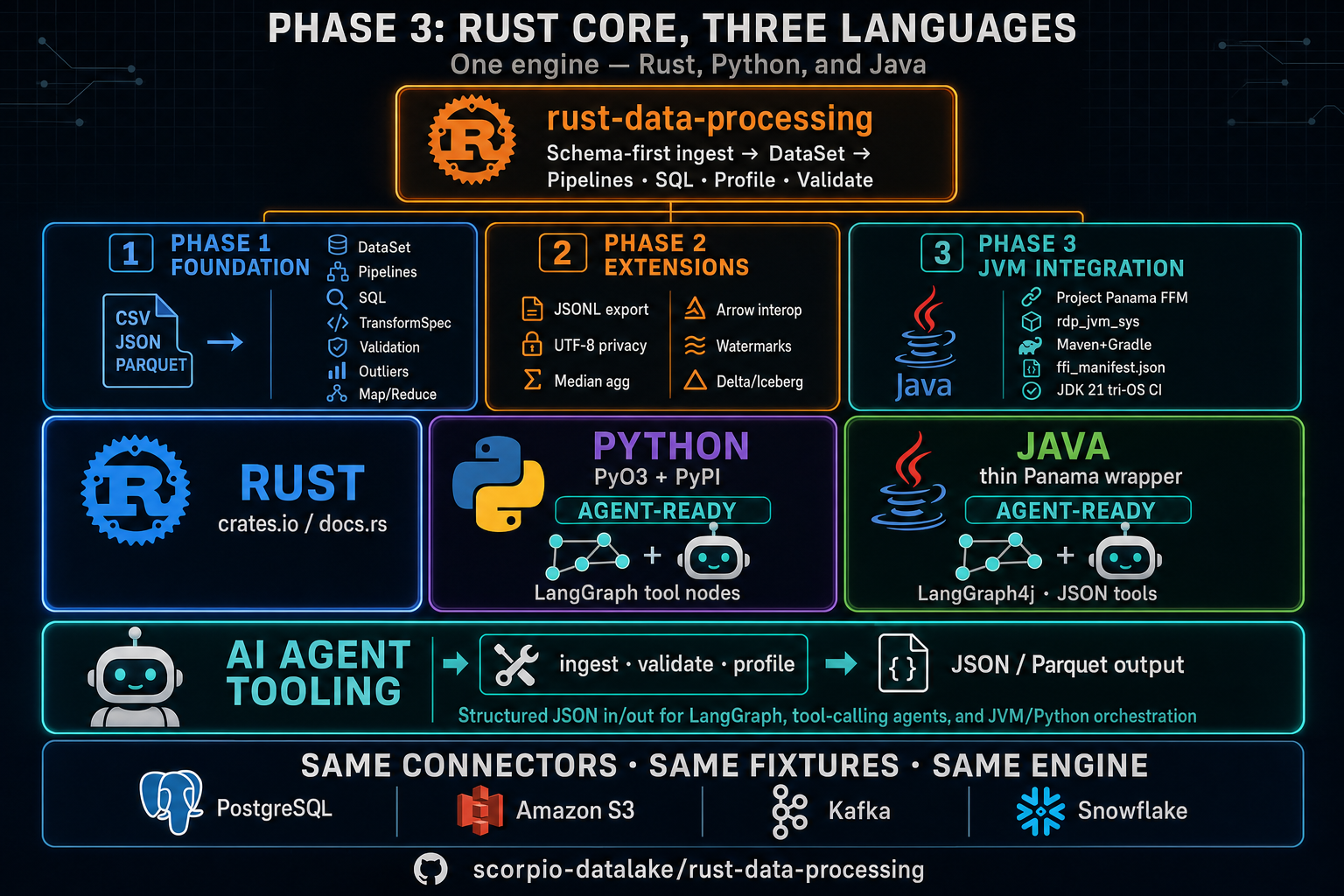
Phase 3 overview (infographic): one Rust engine; Python and JVM
bindings; Phase 1–2 ingest → DataSet → pipelines, SQL,
profile, validate; agent-ready JSON in/out; shared connectors (Postgres,
S3, Kafka, Snowflake).
Add to your Cargo.toml (example):
[dependencies]
rust-data-processing = { path = "." }Ingest a file using a schema:
use rust_data_processing::ingestion::{ingest_from_path, IngestionOptions};
use rust_data_processing::types::{DataType, Field, Schema};
fn main() -> Result<(), rust_data_processing::IngestionError> {
let schema = Schema::new(vec![
Field::new("id", DataType::Int64),
Field::new("name", DataType::Utf8),
]);
// Auto-detect format from file extension (.csv/.json/.parquet/...).
let ds = ingest_from_path("tests/fixtures/people.csv", &schema, &IngestionOptions::default())?;
println!("rows={}", ds.row_count());
Ok(())
}Prefer builder-style options when you only need to override a couple knobs:
use rust_data_processing::ingestion::IngestionOptionsBuilder;
use rust_data_processing::types::{DataType, Field, Schema};
fn main() -> Result<(), rust_data_processing::IngestionError> {
let schema = Schema::new(vec![
Field::new("id", DataType::Int64),
Field::new("name", DataType::Utf8),
]);
let ds = IngestionOptionsBuilder::new()
.ingest_from_path("tests/fixtures/people.csv", &schema)?;
println!("rows={}", ds.row_count());
Ok(())
}Use rust_data_processing::pipeline::DataFrame for a
DataFrame-centric pipeline API that compiles to a lazy plan and collects
into a DataSet:
use rust_data_processing::pipeline::{DataFrame, Predicate};
use rust_data_processing::types::{DataSet, DataType, Field, Schema, Value};
let ds = DataSet::new(
Schema::new(vec![
Field::new("id", DataType::Int64),
Field::new("active", DataType::Bool),
Field::new("score", DataType::Float64),
]),
vec![
vec![Value::Int64(1), Value::Bool(true), Value::Float64(10.0)],
vec![Value::Int64(2), Value::Bool(true), Value::Float64(20.0)],
vec![Value::Int64(3), Value::Bool(false), Value::Float64(30.0)],
],
);
let out = DataFrame::from_dataset(&ds)?
.filter(Predicate::Eq {
column: "active".to_string(),
value: Value::Bool(true),
})?
.multiply_f64("score", 2.0)?
.collect()?;
assert_eq!(out.row_count(), 2);The rust_data_processing::sql module compiles SQL into a
Polars lazy plan and returns a pipeline::DataFrame.
Single-table query (table name is df):
use rust_data_processing::pipeline::DataFrame;
use rust_data_processing::sql;
let out = sql::query(
&DataFrame::from_dataset(&ds)?,
"SELECT id, score FROM df WHERE active = TRUE ORDER BY id DESC LIMIT 10",
)?
.collect()?;Multi-table JOINs via a context:
use rust_data_processing::pipeline::DataFrame;
use rust_data_processing::sql;
let mut ctx = sql::Context::new();
ctx.register("people", &DataFrame::from_dataset(&people)?)?;
ctx.register("scores", &DataFrame::from_dataset(&scores)?)?;
let out = ctx
.execute("SELECT p.id, p.name, s.score FROM people p JOIN scores s ON p.id = s.id")?
.collect()?;Enable the feature:
cargo test --features db_connectorxExample (Postgres):
use rust_data_processing::ingestion::ingest_from_db_infer;
// Example: cxprotocol=binary for Postgres.
let ds = ingest_from_db_infer(
"postgresql://user:pass@localhost:5432/db?cxprotocol=binary",
"SELECT id, score, active FROM my_table",
)?;
println!("rows={}", ds.row_count());Enable the feature (includes object store + SFTP/FTP):
cargo test --features cloud_connectors
cargo run --features cloud_connectors --example file_transfer_ingest -- `
"ftp://etl_user:PASS@ftp.example.com:21/rdp/incoming/data.json"Set secrets on the process: FTP_PASSWORD,
SFTP_PASSWORD, or SFTP_PRIVATE_KEY_PATH (see
CONNECTORS.md and CLOUD_AUTH.md).
use rust_data_processing::ingestion::{ingest_from_file_transfer_uri, IngestionOptions};
let ds = ingest_from_file_transfer_uri(
"sftp://etl_user@sftp.example.com:22/rdp/incoming/data.parquet",
&schema,
&IngestionOptions::default(),
)?;JVM pipelines use sources.file_transfer_uris in JSON
(same URIs; Rust performs the download).
Integration-tested (Docker):
integration_testing/CloudConnectors/ — SFTP/FTP import and
S3/GCS/Azure export + read-back via pipeline JSON. Step-by-step: integration_testing/integration_testing_details.md.
use rust_data_processing::ingestion::{
export_dataset_to_object_store_uri, ingest_from_object_store_uri, IngestionOptions,
IngestionFormat,
};
// Set AWS_*, GOOGLE_APPLICATION_CREDENTIALS, or AZURE_* on this process (see CONNECTORS.md).
let ds = ingest_from_object_store_uri(
"s3://rdp-cloud-s3/out.parquet",
&schema,
&IngestionOptions { format: Some(IngestionFormat::Parquet), ..Default::default() },
)?;
export_dataset_to_object_store_uri("gs://rdp-cloud-gcs/out.parquet", &ds)?;Integration tests use
kind: object_store pipeline sinks and
object_store_uris read-back — see integration_testing/scripts/cloud_pipeline.py.
Build: cargo build --features kafka. Examples:
examples/kafka_elt_stream.rs,
examples/kafka_elt_byo_load.rs. Full guide: KAFKA_ELT.md.
Integration-tested:
integration_testing/Kafka/ — one Uber CSV row per message
via rdp_kafka_export_dataset_json / poll FFI (see
integration_testing/Kafka/rust/src/rdp_kafka.rs).
transform::TransformSpec is a serde-friendly “mapping
spec” that compiles to our Polars-backed pipeline wrappers while keeping
the public API engine-agnostic.
use rust_data_processing::pipeline::CastMode;
use rust_data_processing::transform::{TransformSpec, TransformStep};
use rust_data_processing::types::{DataSet, DataType, Field, Schema, Value};
let ds = DataSet::new(
Schema::new(vec![
Field::new("id", DataType::Int64),
Field::new("score", DataType::Int64),
Field::new("weather", DataType::Utf8),
]),
vec![
vec![Value::Int64(1), Value::Int64(10), Value::Utf8("drizzle".to_string())],
vec![Value::Int64(2), Value::Null, Value::Utf8("rain".to_string())],
],
);
let out_schema = Schema::new(vec![
Field::new("id", DataType::Int64),
Field::new("score_f", DataType::Float64),
Field::new("wx", DataType::Utf8),
]);
let spec = TransformSpec::new(out_schema.clone())
.with_step(TransformStep::Rename {
pairs: vec![("weather".to_string(), "wx".to_string())],
})
.with_step(TransformStep::Rename {
pairs: vec![("score".to_string(), "score_f".to_string())],
})
.with_step(TransformStep::Cast {
column: "score_f".to_string(),
to: DataType::Float64,
mode: CastMode::Lossy,
})
.with_step(TransformStep::FillNull {
column: "score_f".to_string(),
value: Value::Float64(0.0),
})
.with_step(TransformStep::Select {
columns: vec!["id".to_string(), "score_f".to_string(), "wx".to_string()],
});
let out = spec.apply(&ds)?;
assert_eq!(out.schema, out_schema);Use profiling::profile_dataset to compute common
metrics. For large data, start with deterministic sampling via
Head(n).
use rust_data_processing::profiling::{profile_dataset, ProfileOptions, SamplingMode};
use rust_data_processing::types::{DataSet, DataType, Field, Schema, Value};
let ds = DataSet::new(
Schema::new(vec![Field::new("score", DataType::Float64)]),
vec![vec![Value::Float64(1.0)], vec![Value::Null], vec![Value::Float64(3.0)]],
);
let rep = profile_dataset(
&ds,
&ProfileOptions {
sampling: SamplingMode::Head(2),
quantiles: vec![0.5],
},
)?;
assert_eq!(rep.row_count, 2);
assert_eq!(rep.columns[0].null_count, 1);Define checks with validation::ValidationSpec and render
the report as JSON/Markdown.
use rust_data_processing::validation::{validate_dataset, Check, Severity, ValidationSpec};
use rust_data_processing::types::{DataSet, DataType, Field, Schema, Value};
let ds = DataSet::new(
Schema::new(vec![Field::new("email", DataType::Utf8)]),
vec![
vec![Value::Utf8("ada@example.com".to_string())],
vec![Value::Null],
vec![Value::Utf8("not-an-email".to_string())],
],
);
let spec = ValidationSpec::new(vec![
Check::NotNull { column: "email".to_string(), severity: Severity::Error },
Check::RegexMatch {
column: "email".to_string(),
pattern: r"^[^@]+@[^@]+\.[^@]+$".to_string(),
severity: Severity::Warn,
strict: true,
},
]);
let rep = validate_dataset(&ds, &spec)?;
assert!(rep.summary.total_checks >= 2);use rust_data_processing::outliers::{detect_outliers_dataset, OutlierMethod, OutlierOptions};
use rust_data_processing::profiling::SamplingMode;
use rust_data_processing::types::{DataSet, DataType, Field, Schema, Value};
let ds = DataSet::new(
Schema::new(vec![Field::new("x", DataType::Float64)]),
vec![
vec![Value::Float64(1.0)],
vec![Value::Float64(1.0)],
vec![Value::Float64(1.0)],
vec![Value::Float64(1000.0)],
],
);
let rep = detect_outliers_dataset(
&ds,
"x",
OutlierMethod::Iqr { k: 1.5 },
&OutlierOptions { sampling: SamplingMode::Full, max_examples: 3 },
)?;
assert!(rep.outlier_count >= 1);The cdc module defines crate-owned boundary types for
CDC events without picking a concrete CDC implementation dependency.
use rust_data_processing::cdc::{CdcEvent, CdcOp, RowImage, SourceMeta, TableRef};
use rust_data_processing::types::Value;
let ev = CdcEvent {
meta: SourceMeta { source: Some("db".to_string()), checkpoint: None },
table: TableRef::with_schema("public", "users"),
op: CdcOp::Insert,
before: None,
after: Some(RowImage::new(vec![
("id".to_string(), Value::Int64(1)),
("name".to_string(), Value::Utf8("Ada".to_string())),
])),
};
assert_eq!(ev.op, CdcOp::Insert);Rename + cast + fill nulls:
use rust_data_processing::pipeline::DataFrame;
use rust_data_processing::types::{DataSet, DataType, Field, Schema, Value};
let ds = DataSet::new(
Schema::new(vec![
Field::new("id", DataType::Int64),
Field::new("score", DataType::Int64),
]),
vec![vec![Value::Int64(1), Value::Int64(10)], vec![Value::Int64(2), Value::Null]],
);
let out = DataFrame::from_dataset(&ds)?
.rename(&[("score", "score_i")])?
.cast("score_i", DataType::Float64)?
.fill_null("score_i", Value::Float64(0.0))?
.collect()?;Group-by aggregates:
use rust_data_processing::pipeline::{Agg, DataFrame};
use rust_data_processing::types::{DataSet, DataType, Field, Schema, Value};
let ds = DataSet::new(
Schema::new(vec![
Field::new("grp", DataType::Utf8),
Field::new("score", DataType::Float64),
]),
vec![
vec![Value::Utf8("A".to_string()), Value::Float64(1.0)],
vec![Value::Utf8("A".to_string()), Value::Float64(2.0)],
vec![Value::Utf8("B".to_string()), Value::Null],
],
);
let out = DataFrame::from_dataset(&ds)?
.group_by(
&["grp"],
&[
Agg::Sum {
column: "score".to_string(),
alias: "sum_score".to_string(),
},
Agg::CountRows {
alias: "cnt".to_string(),
},
],
)?
.collect()?;Per-key mean, sample std dev, and count-distinct (e.g. categorical cardinality per group):
use rust_data_processing::pipeline::{Agg, DataFrame};
use rust_data_processing::processing::VarianceKind;
use rust_data_processing::types::{DataSet, DataType, Field, Schema, Value};
let ds = DataSet::new(
Schema::new(vec![
Field::new("grp", DataType::Utf8),
Field::new("score", DataType::Float64),
Field::new("label", DataType::Utf8),
]),
vec![
vec![Value::Utf8("A".to_string()), Value::Float64(10.0), Value::Utf8("x".to_string())],
vec![Value::Utf8("A".to_string()), Value::Float64(20.0), Value::Utf8("y".to_string())],
vec![Value::Utf8("B".to_string()), Value::Null, Value::Utf8("z".to_string())],
],
);
let _out = DataFrame::from_dataset(&ds)?
.group_by(
&["grp"],
&[
Agg::Mean {
column: "score".to_string(),
alias: "mu_score".to_string(),
},
Agg::StdDev {
column: "score".to_string(),
alias: "sd_score".to_string(),
kind: VarianceKind::Sample,
},
Agg::CountDistinctNonNull {
column: "label".to_string(),
alias: "n_labels".to_string(),
},
],
)?
.collect()?;Semantics (nulls, all-null groups, SUM
vs MEAN, casting): see docs/REDUCE_AGG_SEMANTICS.md.
More API examples: API.md §
Processing pipelines.
Join two DataFrames:
use rust_data_processing::pipeline::{DataFrame, JoinKind};
use rust_data_processing::types::{DataSet, DataType, Field, Schema, Value};
let people = DataSet::new(
Schema::new(vec![
Field::new("id", DataType::Int64),
Field::new("name", DataType::Utf8),
]),
vec![
vec![Value::Int64(1), Value::Utf8("Ada".to_string())],
vec![Value::Int64(2), Value::Utf8("Grace".to_string())],
],
);
let scores = DataSet::new(
Schema::new(vec![Field::new("id", DataType::Int64), Field::new("score", DataType::Float64)]),
vec![
vec![Value::Int64(1), Value::Float64(9.0)],
vec![Value::Int64(3), Value::Float64(7.0)],
],
);
let out = DataFrame::from_dataset(&people)?
.join(DataFrame::from_dataset(&scores)?, &["id"], &["id"], JoinKind::Inner)?
.collect()?;Once you have a DataSet (typically from
ingestion::ingest_from_path), you can apply in-memory
transformations using rust_data_processing::processing:
filter(&DataSet, predicate) -> DataSetmap(&DataSet, mapper) -> DataSetreduce(&DataSet, column, ReduceOp) -> Option<Value>
— includes mean, variance, std
dev (VarianceKind::{Population, Sample}),
sum of squares, L2 norm, count
distinct (non-null), plus count /
sum / min / maxfeature_wise_mean_std(&DataSet, &[&str], VarianceKind)
— one pass over rows for mean + std on several numeric columns
(FeatureMeanStd)arg_max_row / arg_min_row — first row
index where a column is max/min (ties: smallest index)top_k_by_frequency — top‑(k)
(value, count) pairs for label-style columnsPolars-backed equivalents for whole-frame scalars:
pipeline::DataFrame::reduce,
feature_wise_mean_std. Semantics: docs/REDUCE_AGG_SEMANTICS.md.
Example:
use rust_data_processing::processing::{filter, map, reduce, ReduceOp};
use rust_data_processing::types::{DataSet, DataType, Field, Schema, Value};
let schema = Schema::new(vec![
Field::new("id", DataType::Int64),
Field::new("active", DataType::Bool),
Field::new("score", DataType::Float64),
]);
let ds = DataSet::new(
schema,
vec![
vec![Value::Int64(1), Value::Bool(true), Value::Float64(10.0)],
vec![Value::Int64(2), Value::Bool(false), Value::Float64(20.0)],
vec![Value::Int64(3), Value::Bool(true), Value::Null],
],
);
let active_idx = ds.schema.index_of("active").unwrap();
let filtered = filter(&ds, |row| matches!(row.get(active_idx), Some(Value::Bool(true))));
let mapped = map(&filtered, |row| {
let mut out = row.to_vec();
if let Some(Value::Float64(v)) = out.get(2) {
out[2] = Value::Float64(v * 1.1);
}
out
});
let sum = reduce(&mapped, "score", ReduceOp::Sum).unwrap();
assert_eq!(sum, Value::Float64(11.0));use rust_data_processing::processing::{reduce, ReduceOp, VarianceKind};
use rust_data_processing::types::{DataSet, DataType, Field, Schema, Value};
let ds = DataSet::new(
Schema::new(vec![
Field::new("x", DataType::Float64),
Field::new("cat", DataType::Utf8),
]),
vec![
vec![Value::Float64(2.0), Value::Utf8("a".to_string())],
vec![Value::Float64(4.0), Value::Utf8("b".to_string())],
],
);
let mean = reduce(&ds, "x", ReduceOp::Mean).unwrap();
let std_s = reduce(&ds, "x", ReduceOp::StdDev(VarianceKind::Sample)).unwrap();
let l2 = reduce(&ds, "x", ReduceOp::L2Norm).unwrap();
let d = reduce(&ds, "cat", ReduceOp::CountDistinctNonNull).unwrap();
// mean == 3.0, std_s is sqrt(sample var of [2,4]), l2 == hypot(2,4), d == 2 distinct labels
assert!(matches!(mean, Value::Float64(_)));
assert!(matches!(d, Value::Int64(2)));DataFrame::reduce (same ReduceOp)use rust_data_processing::pipeline::DataFrame;
use rust_data_processing::processing::{reduce, ReduceOp};
use rust_data_processing::types::{DataSet, DataType, Field, Schema, Value};
let ds = DataSet::new(
Schema::new(vec![Field::new("x", DataType::Float64)]),
vec![vec![Value::Float64(1.0)], vec![Value::Float64(3.0)]],
);
let mem = reduce(&ds, "x", ReduceOp::Mean).unwrap();
let pol = DataFrame::from_dataset(&ds).unwrap().reduce("x", ReduceOp::Mean).unwrap().unwrap();
assert_eq!(mem, pol);use rust_data_processing::pipeline::DataFrame;
use rust_data_processing::processing::{feature_wise_mean_std, VarianceKind};
use rust_data_processing::types::{DataSet, DataType, Field, Schema, Value};
let ds = DataSet::new(
Schema::new(vec![
Field::new("a", DataType::Int64),
Field::new("b", DataType::Float64),
]),
vec![
vec![Value::Int64(1), Value::Float64(10.0)],
vec![Value::Int64(3), Value::Float64(20.0)],
],
);
let cols = ["a", "b"];
let mem = feature_wise_mean_std(&ds, &cols, VarianceKind::Sample).unwrap();
let pol = DataFrame::from_dataset(&ds)
.unwrap()
.feature_wise_mean_std(&cols, VarianceKind::Sample)
.unwrap();
assert_eq!(mem[0].0, pol[0].0);use rust_data_processing::processing::{arg_max_row, top_k_by_frequency};
use rust_data_processing::types::{DataSet, DataType, Field, Schema, Value};
let ds = DataSet::new(
Schema::new(vec![
Field::new("id", DataType::Int64),
Field::new("region", DataType::Utf8),
]),
vec![
vec![Value::Int64(1), Value::Utf8("west".to_string())],
vec![Value::Int64(2), Value::Utf8("east".to_string())],
vec![Value::Int64(3), Value::Utf8("west".to_string())],
],
);
let (_row, _val) = arg_max_row(&ds, "id").unwrap().unwrap();
let top = top_k_by_frequency(&ds, "region", 2).unwrap();
assert!(!top.is_empty());If you want parallel filter/map, plus
throttling and real-time metrics, use
rust_data_processing::execution:
use rust_data_processing::execution::{ExecutionEngine, ExecutionOptions};
use rust_data_processing::processing::ReduceOp;
use rust_data_processing::types::{DataSet, DataType, Field, Schema, Value};
let schema = Schema::new(vec![
Field::new("id", DataType::Int64),
Field::new("active", DataType::Bool),
Field::new("score", DataType::Float64),
]);
let ds = DataSet::new(
schema,
vec![
vec![Value::Int64(1), Value::Bool(true), Value::Float64(10.0)],
vec![Value::Int64(2), Value::Bool(false), Value::Float64(20.0)],
vec![Value::Int64(3), Value::Bool(true), Value::Null],
],
);
let engine = ExecutionEngine::new(ExecutionOptions {
num_threads: Some(4),
chunk_size: 1_024,
max_in_flight_chunks: 4,
});
let active_idx = ds.schema.index_of("active").unwrap();
let filtered = engine.filter_parallel(&ds, |row| matches!(row.get(active_idx), Some(Value::Bool(true))));
let mapped = engine.map_parallel(&filtered, |row| row.to_vec());
let sum = engine.reduce(&mapped, "score", ReduceOp::Sum).unwrap();
let metrics = engine.metrics().snapshot();
println!("rows_processed={}, elapsed={:?}", metrics.rows_processed, metrics.elapsed);use rust_data_processing::processing::{reduce, ReduceOp, VarianceKind};
use rust_data_processing::types::{DataSet, DataType, Field, Schema, Value};
let schema = Schema::new(vec![Field::new("score", DataType::Float64)]);
let ds = DataSet::new(schema, vec![vec![Value::Float64(1.0)], vec![Value::Null]]);
assert_eq!(reduce(&ds, "score", ReduceOp::Count), Some(Value::Int64(2)));
assert_eq!(reduce(&ds, "score", ReduceOp::Sum), Some(Value::Float64(1.0)));
assert_eq!(reduce(&ds, "missing", ReduceOp::Sum), None);
let all_null = DataSet::new(
Schema::new(vec![Field::new("x", DataType::Float64)]),
vec![vec![Value::Null], vec![Value::Null]],
);
assert_eq!(reduce(&all_null, "x", ReduceOp::Mean), Some(Value::Null));
assert_eq!(
reduce(&all_null, "x", ReduceOp::Variance(VarianceKind::Sample)),
Some(Value::Null)
);Criterion benchmarks live under benches/ (currently
benches/pipelines.rs).
cargo bench --bench pipelinesAdditional benchmark targets:
cargo bench --bench ingestion
cargo bench --bench map_reduce
reduce); arg_max /
top_k_by_frequency; Polars group_by
with mean/std/count-distinct-style Aggscargo bench --bench profiling
profiling::profile_dataset (full vs head
sampling)cargo bench --bench validation
validation::validate_dataset (built-in
checks and reporting overhead)cargo bench --bench outliers
outliers::detect_outliers_dataset (full vs
sampled)Convenience runner (Windows / PowerShell):
./scripts/run_benchmarks.ps1 -Quickuse std::sync::Arc;
use rust_data_processing::ingestion::{
ingest_from_path, IngestionOptions, IngestionSeverity, StdErrObserver,
};
use rust_data_processing::types::{DataType, Field, Schema};
fn main() -> Result<(), rust_data_processing::IngestionError> {
let schema = Schema::new(vec![Field::new("id", DataType::Int64)]);
let opts = IngestionOptions {
observer: Some(Arc::new(StdErrObserver::default())),
alert_at_or_above: IngestionSeverity::Critical,
..Default::default()
};
// Missing files are treated as Critical (and will trigger `on_alert` at this threshold).
let _ = ingest_from_path("does_not_exist.csv", &schema, &opts).unwrap_err();
Ok(())
}